Salvatore Barbagallo
Combining 7+ years in clinical genomics with computational engineering, building reproducible NGS pipelines, ML models, and data workflows that transform biological data into decisions.
About
I combine clinical and genomics laboratory experience with data analysis and process automation to build reliable pipelines, reporting tools, and QC workflows that turn complex biological data into usable results. My background spans regulated clinical environments where I built Python-driven tools, automated QC pipelines, and worked with NGS from library prep through to clinical reporting.
Currently pursuing an MSc in Bioinformatics at Atlantic Technological University, strengthening computational analysis and reproducible pipeline development and automation.
Projects
View all on GitHub ↗Featured Projects
View details
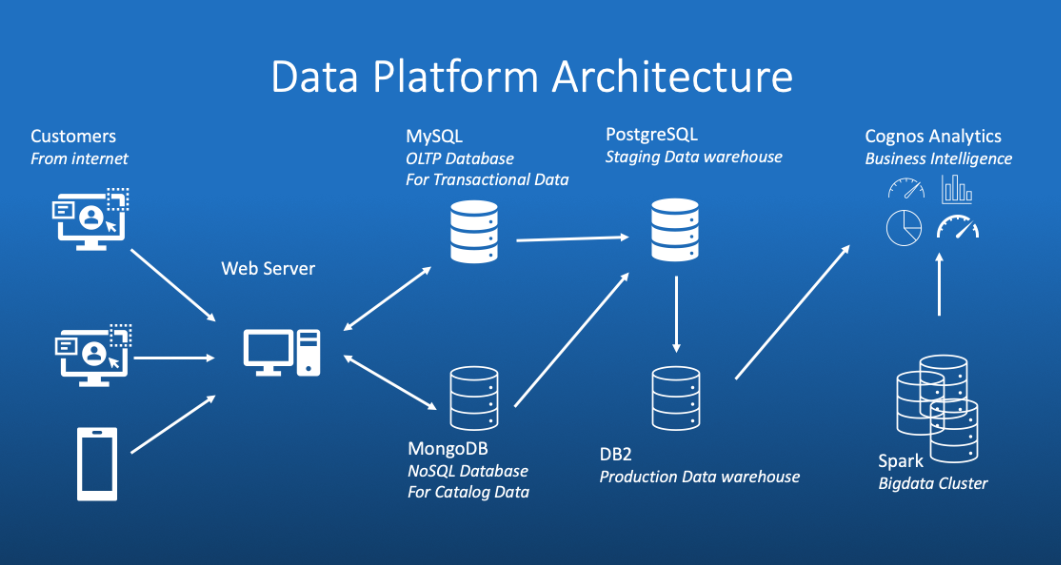
- Objective: Build a structured e-commerce data platform that connects operational sales data, NoSQL product data, warehouse modelling, reporting outputs, and scalable analytics practice.
- Approach: Reorganised the IBM Data Engineering capstone into a clean portfolio repository, fixed warehouse SQL inconsistencies, loaded dimensional tables into PostgreSQL, and generated validated analytical CSV outputs.
- Outcome: Produced a reproducible data engineering artefact with 300,000 fact rows loaded, warehouse validation notes, sales aggregations by country/category, rollup and cube outputs, ETL scripts, MongoDB commands, Spark notebook, and BI report.
View details
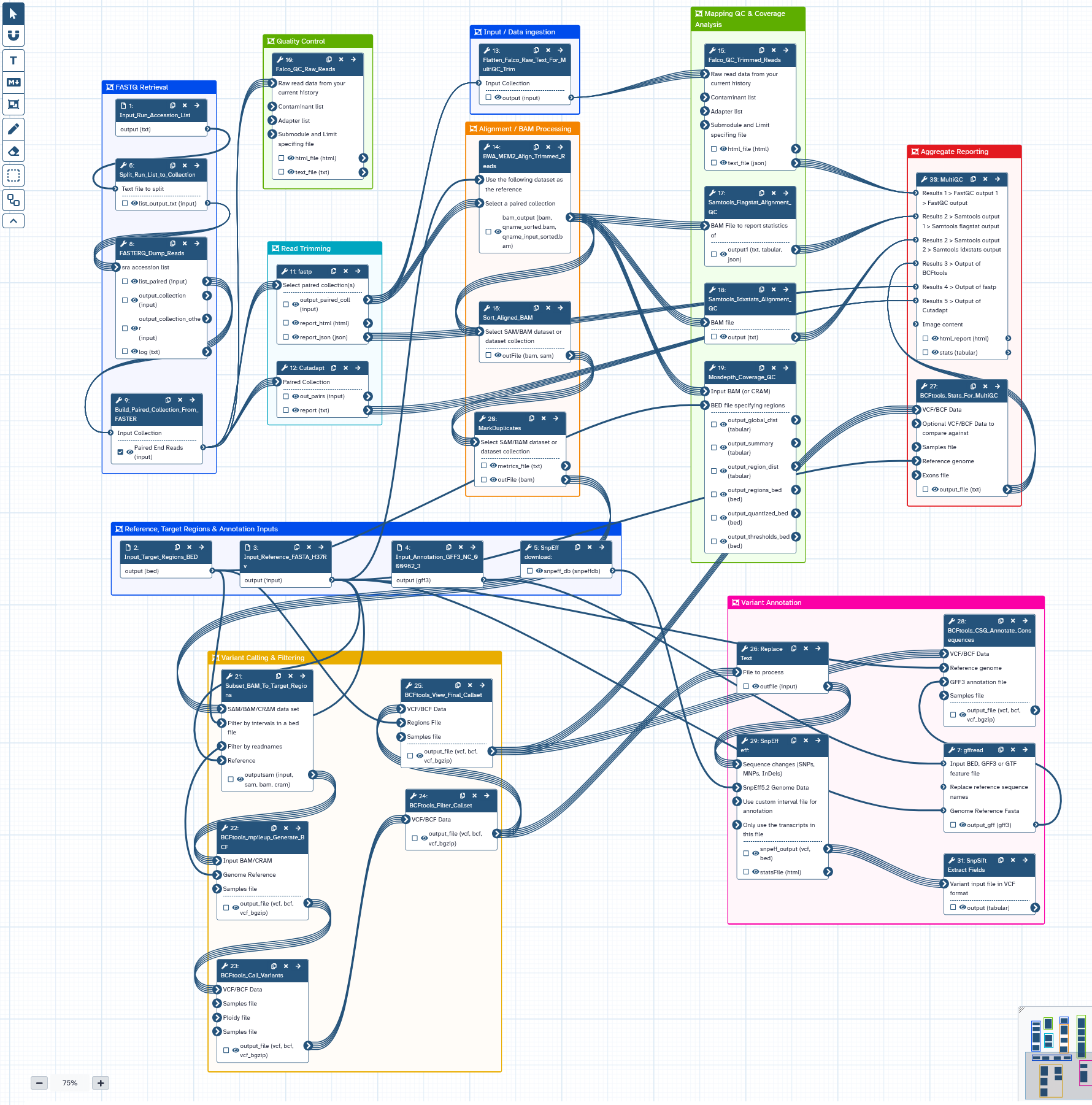
- Problem: Resistance interpretation from WGS data requires a long multi-step workflow with multiple failure points and high risk of inconsistent analysis.
- Action: Built and executed a Galaxy-based workflow covering QC, trimming, alignment, coverage analysis, variant calling, annotation, and IGV-based validation.
- Impact: Produced a structured and reproducible resistance analysis workflow supporting clearer interpretation of clinically relevant loci.
View details
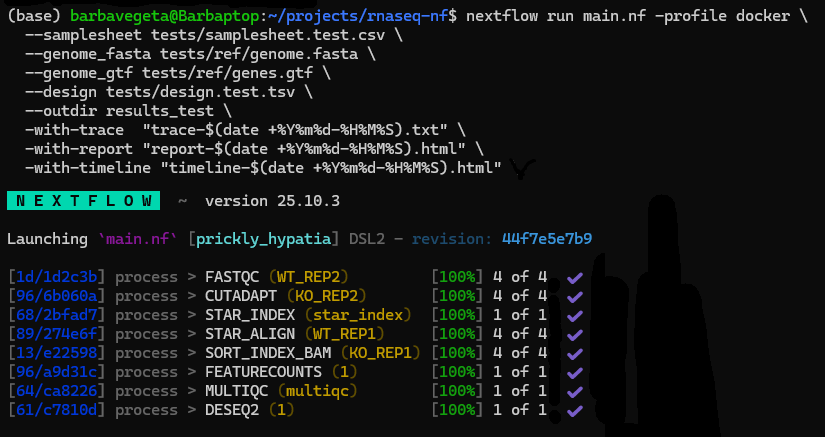
- Problem: RNA-seq analyses are often manually assembled, environment-dependent, and difficult to reproduce across machines.
- Action: Built a containerised Nextflow pipeline integrating FastQC, Cutadapt, STAR, featureCounts, MultiQC, and DESeq2 into a one-command workflow.
- Impact: Reduced setup friction, improved reproducibility, and produced standardised outputs suitable for scalable downstream expression analysis.
Additional Projects
View details
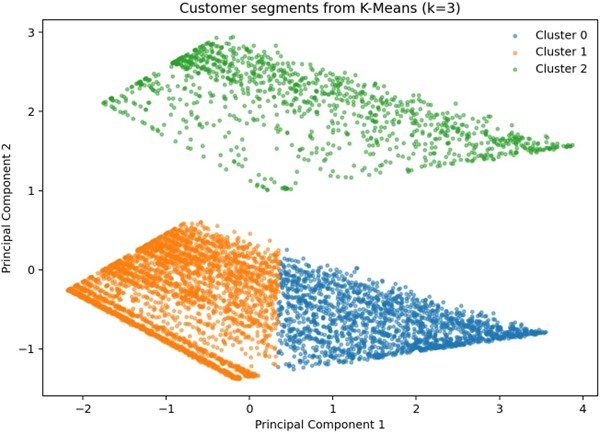
- Objective: Identify meaningful customer segments to enable targeted retention strategies instead of treating churn as a uniform problem.
- Approach: Applied clustering methods on standardised features and selected the final model using silhouette score.
- Outcome: Produced interpretable segments that can guide retention campaigns, onboarding improvements, and pricing strategies.
View details
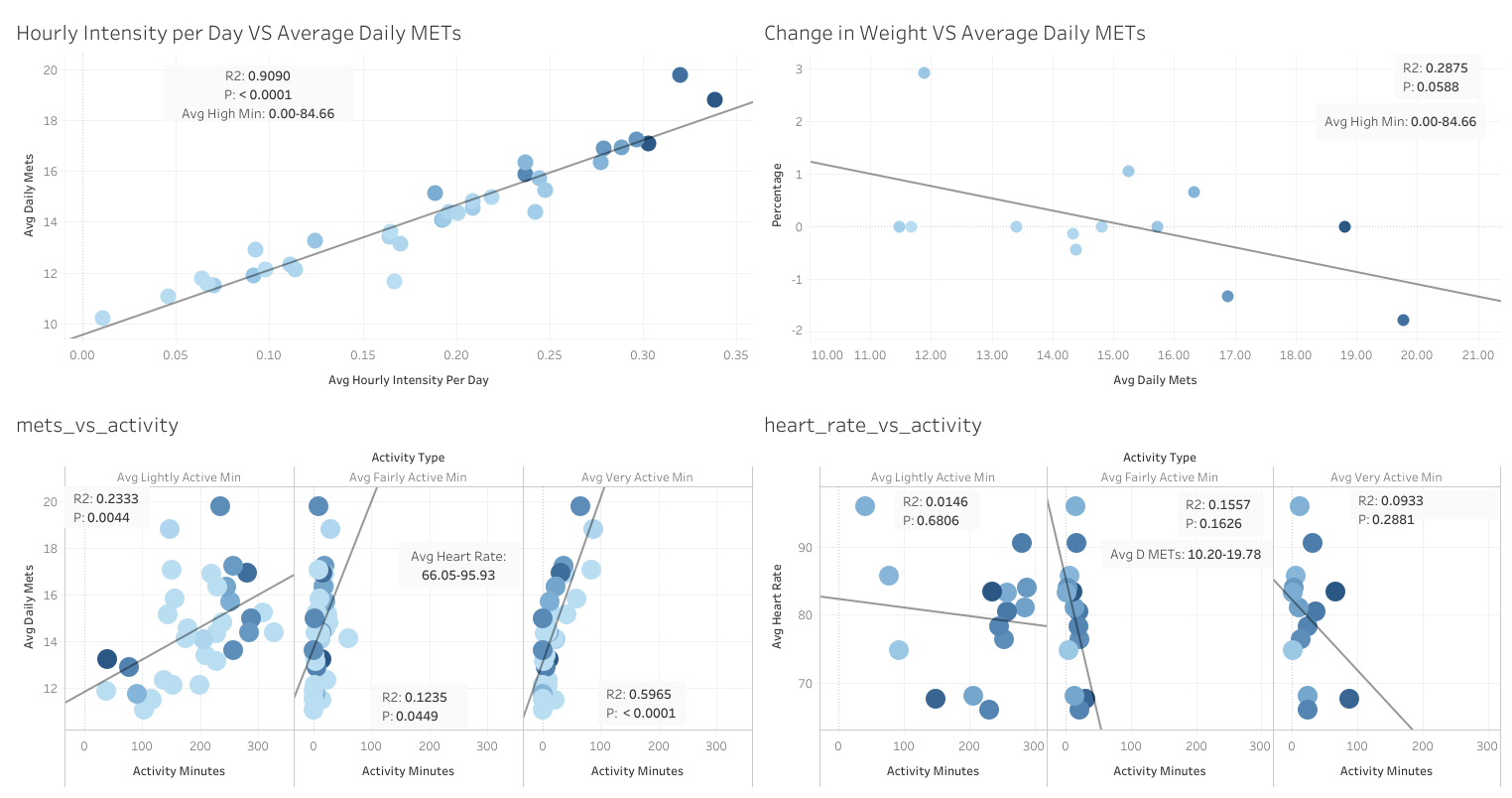
- Problem: Raw Fitbit data was split across multiple files and not directly usable for behavioural analysis or product-facing insight generation.
- Action: Cleaned, merged, and summarised wearable datasets using R, dplyr, and SQLite, then created a Tableau-ready user summary with 15 behavioural and wellness variables.
- Impact: Enabled clearer identification of activity, sleep, and health trends to support data-driven product and marketing recommendations.
View details
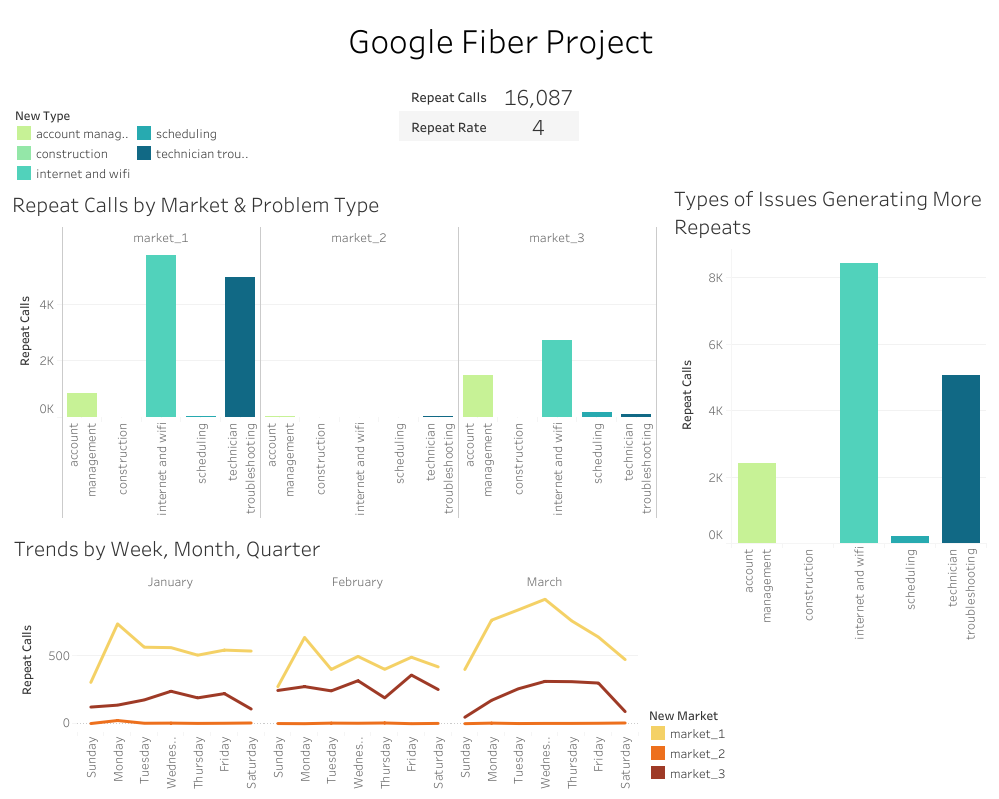
- Problem: Customer contact data was split across regional datasets, making it difficult to understand repeat-contact behaviour and pinpoint service pain points.
- Action: Consolidated 3 datasets into a unified analysis table covering 1,350 records and 85,179 contact events across 5 contact types, then built a Tableau dashboard to surface repeat-contact patterns and operational friction.
- Impact: Turned fragmented customer-support data into a decision-ready BI view that can support targeted service improvements and reduction of avoidable support load.
View details
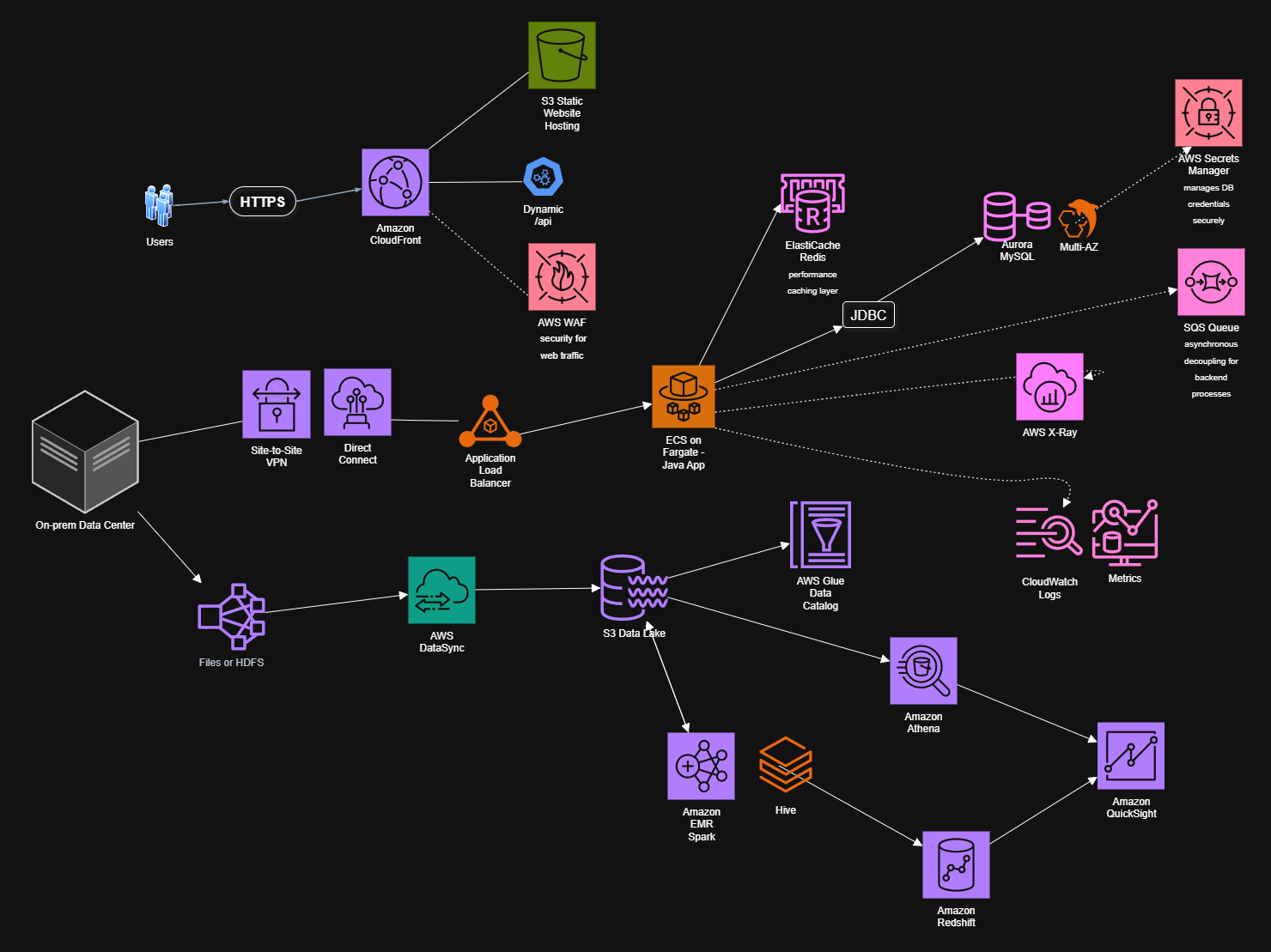
- Objective: Migrate two on-prem workloads, a three-tier web application and a Hadoop-based analytics environment, into a modern AWS environment with managed services.
- Approach: Designed an end-to-end cloud solution using AWS managed services including CloudFront, S3, ECS on Fargate, ALB, Aurora MySQL, ElastiCache, SQS, EMR, Glue, Athena, Redshift, and QuickSight.
- Outcome: Produced a decoupled, fault-tolerant, multi-AZ architecture that modernises both workloads while reducing operational overhead through managed services.
Experience
- Delivered processing and cryopreservation of PBSCs, bone marrow, DLI, and CD34+ enriched products in a regulated clinical environment.
- Generated flow cytometry data on CD3+ and CD34+ populations for time-sensitive clinical decision-making.
- Supported 11 active clinical and ATMP trials, including CAR-T therapies, with responsibility for traceability, documentation quality, and audit-ready data handling in a high-stakes regulated clinical setting.
- Designed Python/Excel tracking tools replacing manual reconciliation, reduced inventory errors by ~30%, saved ~10 hours/week.
- Led digitisation of SOPs and QA documentation, standardising data handling across workflows.
- Processed embryo samples for PGT-A, PGT-SR, and PGT-M testing within a high-throughput clinical genomics pipeline.
- Delivered NGS library preparation and QC across 96–192 samples/run; produced 500+ clinical reports per week.
- Programmed and validated Mosquito HV and Dragonfly liquid handlers, improving workflow scalability and reproducibility.
- Contributed to SOP writing and review, strengthening ISO-compliant laboratory practice.
- Managed sample reception and prepared specimens for Papanicolaou staining.
- Maintained reagents and ensured sample integrity end-to-end.
Education
Certifications
Contact
Let's Connect
Open to opportunities in bioinformatics, data science, and data pipelines and automation. Based in London and remote-friendly.